
The global energy landscape is undergoing a profound transformation, shifting from centralized, fossil-fuel-based generation towards a decentralized, digital, and renewable-centric paradigm. At the heart of this transition lies the critical challenge of intermittency associated with renewable sources like solar and wind. Battery Energy Storage Systems (BESS) have emerged as the cornerstone technology for mitigating this challenge, providing essential services such as energy arbitrage, frequency regulation, peak shaving, and backup power. As the scale and penetration of these systems grow exponentially, managing thousands to millions of individual battery cells within a single installation becomes a task of immense complexity. Traditional Battery Management Systems (BMS), while effective for smaller packs, face significant limitations in handling the sheer volume, velocity, and variety of data generated by grid-scale and large commercial battery energy storage systems. This is where big data technologies offer a revolutionary path forward, enabling not just management, but true intelligence, predictive maintenance, and optimized performance throughout the asset’s lifecycle.
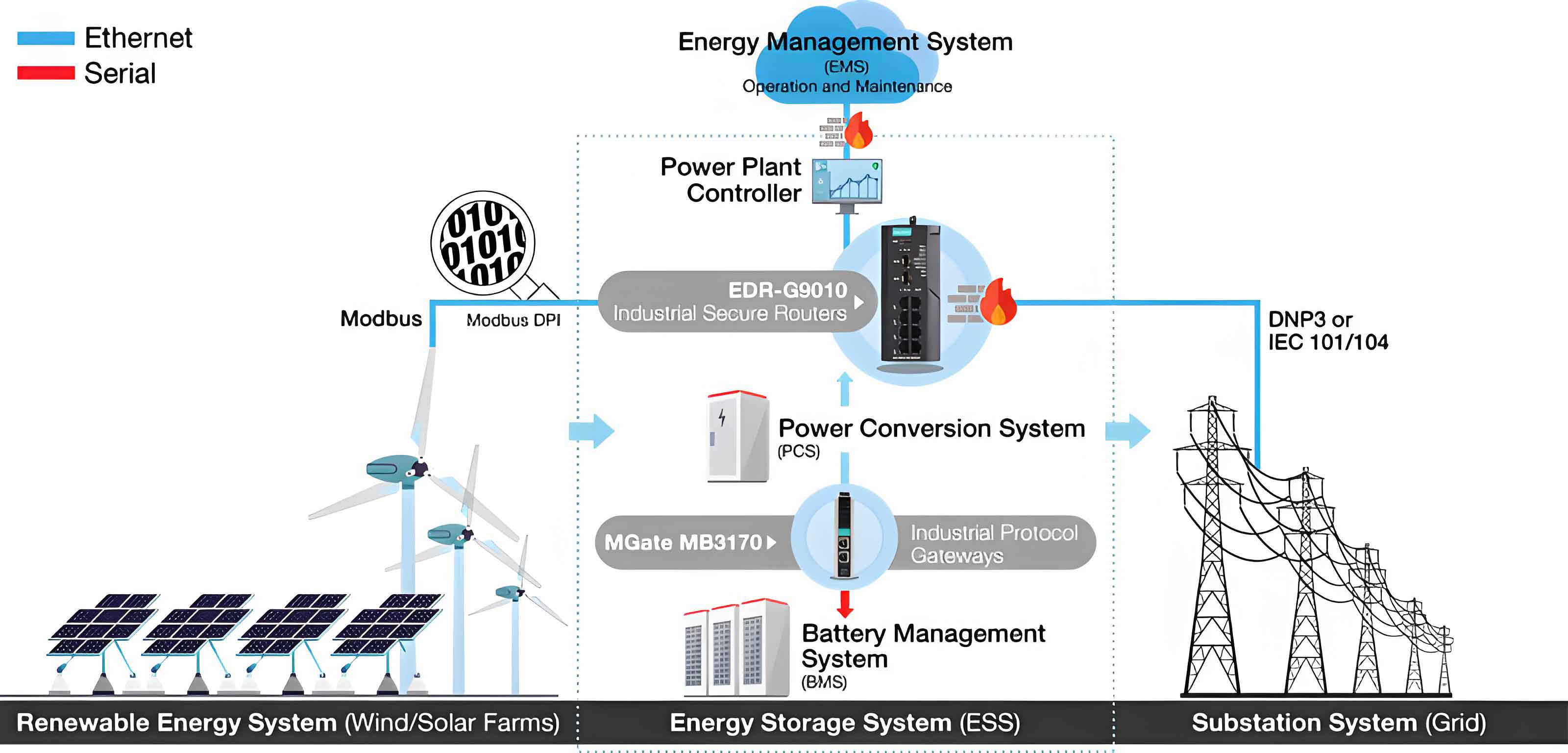
The fundamental challenge in any battery energy storage system arises from cell-to-cell variability. Despite manufacturing controls, individual lithium-ion cells exhibit differences in capacity, internal impedance, self-discharge rate, and aging characteristics. In a series-connected string, the weakest cell dictates the performance of the entire chain. An under-performing cell can limit charge acceptance during charging (leading to under-utilized healthy cells) and cause premature termination during discharge (wasting available energy). In extreme cases, such imbalances can drive individual cells into over-voltage or under-voltage conditions, triggering safety hazards and accelerating degradation. The primary role of a conventional BMS is to monitor cell voltages, temperatures, and currents, perform basic state estimation (like State of Charge – SOC), enforce safe operating limits, and attempt to balance cell voltages. However, its computational models are often simplistic, its data history is limited, and its analysis is reactive rather than predictive.
The operation of a modern, large-scale battery energy storage system is a continuous fountain of high-dimensional time-series data. Each battery module or rack generates streams of data points for voltage, current, temperature (often at multiple sensor points), and sometimes internal resistance. For a 100 MW/200 MWh installation comprising thousands of modules, this can translate into millions of data points per hour. This data holds the key to understanding complex, non-linear battery behaviors, but its scale and complexity render traditional relational databases and analysis tools inadequate. The “Vs” of big data—Volume, Velocity, Variety, Veracity, and Value—are fully applicable. The challenge is to extract actionable insights and long-term value from this data deluge to ensure safety, maximize economic return, and extend system life.
Big Data Architecture for Scalable BESS Management
To harness the power of big data, the architecture of the management system for a battery energy storage system must evolve from a monolithic, embedded controller to a distributed, cloud-native platform. This new architecture typically separates concerns into distinct layers: the Edge Layer, the Data Ingestion & Storage Layer, the Processing & Analytics Layer, and the Application & Visualization Layer.
The Edge Layer consists of the physical BMS units (slave and master controllers) deployed on the battery racks. Their role is enhanced from mere data collection to include local, real-time preprocessing (e.g., filtering noise, calculating simple derivatives) and immediate safety-critical control. They stream condensed data packets to the cloud or central server via robust industrial communication protocols.
The Data Ingestion & Storage Layer is the foundation of the big data platform. It must handle the continuous, high-throughput influx of data from potentially hundreds of data sources. Technologies like Apache Kafka or Pulsar are employed as message queues to buffer and reliably ingest these real-time streams. The data is then persisted in a storage solution designed for time-series data, such as InfluxDB, TimescaleDB, or OpenTSDB. For long-term, deep historical analysis requiring complex queries across massive datasets, the data is also stored in a data lake (e.g., on Hadoop HDFS or cloud object storage like AWS S3) in a structured format like Parquet or ORC. This separation allows for cost-effective storage of “cold” data while keeping “hot,” recent data readily accessible for operational dashboards.
The Processing & Analytics Layer is the computational engine. It employs different frameworks suited for different tasks:
- Stream Processing: For real-time anomaly detection, immediate state estimation updates, and alert generation, frameworks like Apache Flink, Apache Storm, or Spark Streaming analyze data in motion as it arrives through the ingestion layer.
- Batch Processing: For complex, long-running calculations—such as training machine learning models for State of Health (SOH) prediction, performing detailed performance analytics over weeks of data, or optimizing long-term dispatch schedules—frameworks like Apache Spark (on Hadoop YARN or Kubernetes) process the vast datasets stored in the data lake.
The Application Layer exposes the insights to end-users. This includes web-based dashboards for real-time system monitoring, automated reporting tools, APIs for integration with Energy Management Systems (EMS) or grid operators, and interfaces for control signal dispatch.
| Architecture Layer | Key Technologies & Components | Primary Function for BESS |
|---|---|---|
| Edge / Field | Enhanced BMS, IoT Gateways | Data acquisition, real-time safety control, local preprocessing |
| Ingestion & Storage | Apache Kafka, InfluxDB/TimescaleDB, Hadoop HDFS / S3 | High-throughput data ingestion, time-series & long-term historical storage |
| Processing & Analytics | Apache Flink (Streaming), Apache Spark (Batch), ML Frameworks (TensorFlow, PyTorch) | Real-time monitoring, batch analytics, machine learning model execution |
| Application & Visualization | Web Dashboards (Grafana), REST APIs, Control Interfaces | Human-in-the-loop monitoring, system control, integration with external systems |
Advanced State Estimation and Prediction with Big Data
The most critical analytics for any battery energy storage system revolve around accurately estimating internal states that are not directly measurable, primarily State of Charge (SOC) and State of Health (SOH). Traditional BMS methods, like Coulomb counting (ampere-hour integration) or simple look-up tables, are prone to error accumulation and cannot adapt to changing battery conditions. Big data enables a paradigm shift towards adaptive, data-driven, and physics-informed models.
1. Enhanced SOC Estimation: While model-based filters like the Extended Kalman Filter (EKF) or Unscented Kalman Filter (UKF) are standard, their accuracy depends on a precise battery model. Big data allows for the continuous calibration of these models. For instance, the parameters of an equivalent circuit model (ECM) can be estimated in real-time using streaming data and recursive least squares algorithms. A second-order RC model, common for lithium-ion batteries, is described by:
$$V_{terminal}(t) = V_{oc}(SOC(t)) – I(t)R_0 – V_1(t) – V_2(t)$$
where the dynamics of the polarization voltages are:
$$\dot{V_1}(t) = -\frac{V_1(t)}{R_1 C_1} + \frac{I(t)}{C_1}, \quad \dot{V_2}(t) = -\frac{V_2(t)}{R_2 C_2} + \frac{I(t)}{C_2}$$
Here, $V_{oc}$ is the open-circuit voltage (a function of SOC), $I$ is the current, $R_0$ is the ohmic resistance, and $R_1C_1$, $R_2C_2$ represent short-term and long-term polarization dynamics. Using high-frequency operational data, big data platforms can periodically re-estimate parameters like $R_0$, $R_1$, $C_1$, $R_2$, $C_2$, leading to a more accurate state-space model for the Kalman filter, thereby improving SOC estimation.
2. Data-Driven SOH and Remaining Useful Life (RUL) Prediction: SOH, often defined as the ratio of current maximum capacity to initial capacity, is a long-term degradation metric. Predicting it is ideal for big data batch analytics. Machine learning models can be trained on historical data from thousands of cells or entire fleets of battery energy storage systems. Features are engineered from operational data, including:
- Capacity fade trends from periodic full cycles.
- Incremental capacity analysis (dQ/dV curves) derived from charge data.
- Trends in internal resistance growth.
- Statistical features of voltage and temperature distributions across the pack.
- Operational history (average SOC, depth of discharge, C-rates).
Algorithms like Gradient Boosting Machines (XGBoost, LightGBM), Support Vector Regression, or even deep learning models (LSTMs) can learn the complex, non-linear mapping from these features to capacity fade or impedance rise. The predictive power of such models scales with the volume and variety of training data, making big data infrastructure essential.
| Prediction Task | Traditional BMS Approach | Big Data & ML Enhanced Approach | Key Data Features Utilized |
|---|---|---|---|
| State of Charge (SOC) | Coulomb counting, EKF with fixed model | Adaptive EKF/UKF with online parameter identification; Deep learning sequence models (LSTM) | Voltage, current, temperature sequences; parameter drift over time |
| State of Health (SOH) | Periodic capacity test, lookup table based on cycle count | Machine learning regression (XGBoost, SVR) on historical degradation data; Differential Voltage Analysis (dQ/dV) | Capacity fade history, impedance trends, dQ/dV curve features, thermal statistics |
| Remaining Useful Life (RUL) | Linear extrapolation of capacity | Prognostic models (Particle Filtering, LSTM-based sequence prediction) | Full historical degradation trajectory, stress factor profiles |
| Fault & Anomaly Detection | Threshold-based alarms (e.g., over-temperature) | Unsupervised learning (Isolation Forest, Autoencoders); Pattern recognition on time-series | Real-time multivariate sensor streams, deviation from normal operational clusters |
Proactive Safety, Fault Diagnosis, and Fleet Learning
Safety is paramount in a battery energy storage system. Big data moves safety management from a reactive, threshold-based system to a proactive, predictive one. Advanced anomaly detection algorithms can identify subtle deviations in cell behavior long before they reach critical thresholds. Techniques like multivariate statistical process control (PCA, T² and Q statistics) or unsupervised machine learning models (Isolation Forest, One-Class SVM) can establish a “normal operational fingerprint” for each module or cell cluster. Any significant deviation from this fingerprint triggers an early warning, allowing for investigation or preventive maintenance.
Furthermore, when a fault does occur, big data analytics enables root cause diagnosis. By correlating the fault event with terabytes of historical data—operating conditions, preceding charge/discharge profiles, environmental data, and similar events in other systems—analysts can identify patterns and causal factors. This transforms incident analysis from a speculative exercise into a data-driven investigation.
Perhaps the most powerful concept enabled by big data is fleet learning. Data from hundreds or thousands of deployed battery energy storage systems can be aggregated (anonymized and securely) in a central platform. This creates an unparalleled dataset representing diverse chemistries, manufacturers, climates, and usage profiles. Machine learning models trained on this fleet-wide data become significantly more robust and generalizable. Insights gained from one installation experiencing a particular degradation mode can be used to update models and monitoring strategies for all similar installations globally, creating a virtuous cycle of continuous improvement and shared intelligence.
Operational Optimization and Economic Dispatch
Beyond cell-level management, big data analytics optimize the entire battery energy storage system as a grid asset. By integrating high-fidelity battery state predictions with external data streams—such as electricity market prices, weather forecasts for renewable generation, and grid load forecasts—sophisticated optimization algorithms can compute the most profitable or grid-supportive charge/dispatch schedule. These algorithms must factor in the complex degradation costs associated with different usage patterns, which are precisely quantified by the advanced SOH models described earlier.
The objective function for a day-ahead market participant might be formulated as:
$$ \max \sum_{t=1}^{T} \left( \lambda_t^{DA} \cdot P_{discharge}(t) \cdot \Delta t – C_{deg}(t) \right) $$
subject to constraints:
$$ SOC(t+1) = SOC(t) + \frac{\eta_{ch} P_{charge}(t) \Delta t}{E_{cap}} – \frac{P_{discharge}(t) \Delta t}{\eta_{dis} E_{cap}} $$
$$ SOC_{min} \leq SOC(t) \leq SOC_{max} $$
$$ 0 \leq P_{charge}(t) \leq P_{max, ch}, \quad 0 \leq P_{discharge}(t) \leq P_{max, dis} $$
where $\lambda_t^{DA}$ is the day-ahead electricity price, $P$ is power, $\eta$ is efficiency, $E_{cap}$ is the usable capacity, and $C_{deg}(t)$ is the degradation cost for the action at time $t$, derived from a data-driven degradation model. Solving this requires processing large sets of forecast and historical data, a task well-suited for big data platforms.
Challenges and Future Outlook
The integration of big data into battery energy storage system management is not without challenges. Data quality and sensor fidelity are critical; “garbage in, garbage out” holds especially true for complex ML models. Cybersecurity for these connected, critical energy assets is a top concern, requiring robust encryption, access controls, and intrusion detection. The computational cost of continuous advanced analytics also has an energy footprint that must be considered.
Looking ahead, the convergence of big data, artificial intelligence, and high-fidelity physics-based models (digital twins) will define the next generation of BESS intelligence. Edge computing will grow, performing more sophisticated local analytics to reduce latency and bandwidth needs. Standardized data formats and open APIs will facilitate interoperability and the growth of a third-party analytics ecosystem. Ultimately, the battery energy storage system will evolve from a static piece of hardware into a self-learning, adaptive, and optimally performing grid asset, with big data serving as its central nervous system, ensuring safety, longevity, and maximum value in the clean energy future.
| Application Domain | Big Data Technology Enabler | Impact on Battery Energy Storage System |
|---|---|---|
| State Estimation | Stream Processing, Online Parameter Estimation, ML | Higher accuracy SOC/SOH, adaptive to aging and conditions |
| Prognostic Health Management | Batch ML on Data Lakes, Fleet Learning | Predictive maintenance, accurate RUL, reduced downtime |
| Safety & Anomaly Detection | Real-time Stream Analytics, Unsupervised ML | Early warning for thermal runaway, internal shorts, etc. |
| Performance Optimization | Integrated Analytics (Market + Battery Models), Optimization Algorithms | Maximized revenue, minimized degradation, enhanced grid services |
| Fleet & Asset Management | Centralized Data Platform, Comparative Analytics | Benchmarking, warranty validation, improved O&M strategies |